
분산 적재 방식
정적, 동적할당과 buddy system은 메인 메모리 안의 연속된 공간에 하나의 프로세스를 적재하는데 반해
분산 적재 방식은 하나의 프로세스를 특정 단위로 쪼개어 연속되지 않은 공간에 저장이 가능하게 함
paging
프로세스를 동일한 크기의 조각으로 나눔 나눠진 프로세스 각각을 page라고 부름
메모리도 조각으로 나눔 나눠진 조각을 Frame이라고 함
page의 사이즈 = Frame 사이즈 여야 한다.
이렇게 나누는 이유는 프로세스를 page 단위로 쪼개어 여러 frame에 하나의 프로세스의 page들을 분산하여 적재하기 때문에
위의 세 그림을 보면 프로세스 A와 B를 정해진 단위로 쪼개어 메모리의 frame에 적재한 것을 볼 수 있고

밑의 세 그림을 마저 보면 B가 종료되고 D가 할당될 때 연속된 공간이 아니라 분산해서 적재되는 것을 볼 수 있다.
이렇게 하면 프로세스가 정상적으로 실행이 되지 않을 수 있다고 생각되는데,
이를 해결하기 위해 프로세스들은 자신의 page들이 메모리의 어느 위치에 존재하는지 알 수 있는 정보인 page table을 가지고 있다. 아래는 위 그림의 F단계에서 존재하는 각 프로세스의 page table들이다.

불연속적인 프로세스 위치로 인해서 base register, bounds register를 사용하는 기법으로는 메모리 관리가 이루어 지지 않는다.
이제 page라는 개념이 생겼기 때문에
논리주소는 프로세스의 page number와 offset으로 표현 가능하다 ex) (2, 300)

물리주소를 찾기 위해 page table를 조회하고, page number 가 2인 곳에 frame1번이 적혀있다.
이는 저장돼있는 offset을 이용하여 1번 frame의 300번째 물리 주소에 찾으려는 값이 있다는 것을 알 수 있다.

여기서 상대주소와 논리주소가 같다는 걸 알 수 있는데,
프로세스의 상대주소에서 일정 부분을 나눠 몇비트는 page number로, 나머지 비트는 offset으로 사용하면
상대주소에서 바로 논리주소로, 논리주소에서 상대주소로 변환이 가능하다.
이는 page와 frame의 크기가 2의 지수값을 사용할 때 가능한 것이다.

위의 그림에선 logical address가 16비트로 구성되어 있으며
6비트를 page number로, 10비트를 offset으로 저장하고 있다.
page table에 적혀있는 정보와 오프셋을 더해서 논리주소 -> 물리주소로 접근 가능한 것을 볼 수 있다.
문제
page table이 다음과 같고, frame size가 1kb일 때
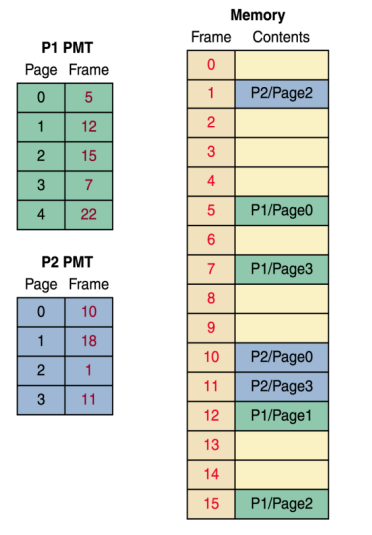
P1의 logical address - 3423를 physical address로 변환하시오.
-> 7 x 1024kb + 423kb = 7591kb
P2의 logical address - 1222를 physical address로 변환하시오.
-> 18 x 1024kb + 222 = 18654kb
paging 기법
장점 - 외부 단편화 문제 해결 (하지만 프로세스의 마지막 frame에서 내부 단편화 메모리가 존재함)
단점 - page table이 존재해야함 - overhead 은근 큼
- logical address -> page table -> physical address 순으로 접근하는 overhead도 있다.
Segmentation
'CS > OS' 카테고리의 다른 글
| 디바이스 드라이버 (0) | 2022.10.17 |
|---|---|
| 메모리의 기본 단위와 저장, 주소 데이터의 저장 (0) | 2022.10.14 |
| 메모리 관리 (0) | 2022.05.31 |
| Deadlock Avoidance (0) | 2022.05.27 |
| Dining Philosophers Problem - 식사하는 철학자 문제 (0) | 2022.05.27 |