ML Lecture
What is Machine Learning
reko_
2023. 4. 15. 13:54
Machine Learing
머신 러닝(machine learning)은 경험을 통해 어떤 성능을 자동으로 개선하는 컴퓨터 알고리즘의 연구이다. 인공지능의 한 분야로 간주된다.
- 인공지능
컴퓨터가 학습할 수 있도록 하는 알고리즘과 기술을 개발하는 분야이다. 가령, 기계 학습을 통해서 수신한 이메일이 스팸인지 아닌지를 구분할 수 있도록 훈련할 수 있다. ex) 알파고의 학습 데이터는 바둑 고수들의 비보 2D matrix
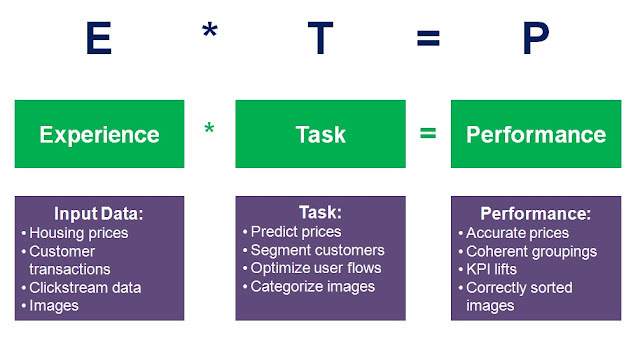
어떤 작업 (Task)의
성능 (Perfomence)을 개선하는데,
경험 (Experience)으로 학습시킨다.
잘 정의된 학습은 T, P, E로 정해진다.
Ex)
T : 체스를 하는 것
P : 상대방을 이기는 것
E : 자신을 상대로 연습 게임을 하는 것
데이터에 사람이 생각하는 정답(label)을 매겨서 계산하고, 사람의 생각과 차이가 나는 오류를 줄여가는 방법으로 수정하고, 이러한 과정을 반복함으로써 사람의 생각과 유사하게 만들 수 있을 것이라는 방법을 생각했다.
이러한 과정을 학습(training)이라고 부르고, 학습 결과로 얻어진 지능을 실제 응용에 적용하는 이 기술을 바로 머신러닝(Machine Learning)이라고 한다.
Feature of ML
- 기존의 알고리즘
- Analytical - 데이터를 내가 직접 분석 하고 이해해야 한다.
- Focused on fiting - 있는 그대로의 사실을 받아들이려고 해야 한다.
- Yield output directly - 내가 이해한 지식 자체가 output이다.
- 머신러닝 알고리즘
- Discriminative/generative - 데이터에 대한 이해 없이 구별하거나 생산해내야 한다. - 데이터의 특성은 기계가 이해한다.
- Focused on generalization - 데이터의 특성을 일반화 해야 한다.
- Yield a program that can geneate output - ouput을 산출해 낼 수 있는 (지식을 알고 있는)모델이 output이 된다.
- 기존의 알고리즘은 내 understanding을 바탕으로 tool을 만들어야 유용하다. 머신러닝 알고리즘은 model 자체가 tool이고 유용하다.
How to Design a Learning System
- choose traning experience (traning data) - 어떤 데이터로 훈련할 것인지, 학습에 사용될 경험이 무엇인지 선택한다.
- choose exactly what is to be learned - 내가 뭘 배울 것인지 문제 정의를 한다. (어떤 데이터를 넣었을 때 어떤 결과가 나오는지 정의한다?)
- choose how to represent the objective - 라벨링, 경험에 대한 결과에 점수를 매긴다.
- choose the algorithm to infer the objective function from the experience! - 알고리즘을 정한다. objective function : 모델을 포함하고 있는 문제 정의 함수

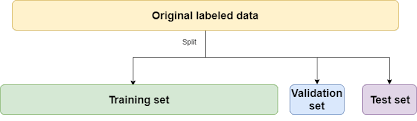
Data Distribution
데이터는 traing, validation, test datasets으로 나뉜다.
- Traing - 모델의 아웃풋이 내가 기대한 값이 나올 수 있도록 파라미터를 조정하는 과정
- Validation - Traning에 사용되지 않은 labeled 데이터들로 Traning된 모델의 성능을 검증하는 과정
- Test - unlabeled data로 모델을 검증하는 과정
Type of Learning
- Supervised Lerning: 라벨이 있는 데이터로 학습
- Unsupervised leaning: 레이블이 없으니까 비슷한 것 끼리 묶는 clustering 기법 등, 라벨이 없는 데이터로 학습
- Semi-supervised learning: 배운걸 기반으로 레이블이 없는 레이블에 레이블링 한다. 이 방법을 사용하면 정확도가 올라간다는 것을 수학적으로 증명 가능하다. 조금 라벨이 있고 없는 데이터들로 학습 보통 회사나 실생활에선 이 경우다. 라벨이 있는 데이터를 기대하긴 어렵다.
- Reinforcement learning: 재수가 없어서 정답만 빼고 시도했다면 최악의 경우 효율이 안좋음 근데 보통 안그럼. 일단 지르고 틀리면 다시 맞으면 칭찬 - action을 했을 때 score가 어떻게 나오는지에 따라 학습 - alphago(바둑알을 어떤 경우에 어디다 둬야 높은 점수가 나오는지 학습)
Why Might Prediction be Wrong
- 관측 값에는 우리가 통제할 수 없는 확률이 존재하기 때문에
- 관측 값에 누락된 값이 존재할 수 있기 때문에,
- 관측 값에 노이즈가 있을 수 있기 때문에
- Representational Bias