
Definition
Linear Regression 은 데이터가 선형적인 특성을 띄고 있을 때, logistic Regression은 정확한 값보다 확률이 의미 있을 때, Decision Tree는 데이터의 특징들이 가지는 어떤 rule이 존재한다고 생각하고 그것을 찾는 것이다.

장점은 거의 모든 데이터에 대해 트리 형식의 모델을 도출할 수 있지만 최악의 경우 전수 조사를 해야 하기 때문에 worst case 성능이 exponential이다.
우리는 트리를 어떻게 만들어야 관측 값에 대한 예측 값을 어떻게 가장 빠르고 정확하게 찾을 수 있는가에 대해 고민해봐야 한다.
Algorithm
성능이 좋은 Decition Tree를 만드는 방법은 엔트로피를 계산하는 것이다. 엔트로피가 클수록 해당 트리는 impurity하다. 우리는 엔트로피가 작은, 질서 있는 트리는 만드는 것이 목표이다.
(정보 엔트로피)
확률이 낮을수록, 어떤 정보일지는 불확실하게 되고, 우리는 이때 '정보가 많다', '엔트로피가 높다'고 표현한다.
정보 이론의 기본은 어떤 사람이 정보를 더 많이 알수록 새롭게 알 수 있는 정보는 적어진다는 것이다.
어떤 사건의 확률이 매우 높다고 가정하자. 우리는 그 사건이 발생해도 별로 놀라지 않는다. 즉, 이 사건은 적은 정보를 제공한다. 반대로, 만약 사건이 불확실하다면, 그 사건이 일어났을 때 훨씬 유용한 정보를 제공한다.
그러므로, 정보량(information content)은 확률에 반비례한다. 이제 만약 더 많은 사건이 일어난다면, 엔트로피는 실제로 한 사건이 일어났을 때, 얻을 것으로 기대되는 평균 정보량을 측정한다.
주사위 던지기와 동전 던지기를 생각해보자. 주사위 던지기에서 일어나는 한 사건의 확률은 동전 던지기에서 일어나는 한 사건의 확률보다 작다. 즉, 여기서 엔트로피는 주사위 던지기가 동전 던지기보다 크다고 할 수 있다.
트리 전체 엔트로피 H(x) [x는 관측 값] 는 다음과 같이 표시할 수 있다.
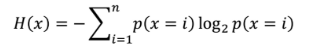
우리가 계산하는 엔트로피는 정보 엔트로피이므로 다음 식을 사용할 수 있다. (이 식은 정보학에서 정의함)
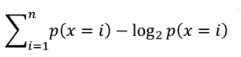
여기서 모델 최적화를 위한 식을 세워야 하는데, IG라는 개념 또한 필요하다.
IG (Information Gain)
정보획득량이란? 분할전 Entropy와 분할 후 Entropy의 차이
이를 수식으로 표현하면 다음과 같다.

여기서, 엔트로피는 불순도를 나타낸다 했다. 즉, 정보획득량이 크다는 것은 어떠한 속성으로 분할 했을 때 불순도가 줄어든다는 것을 의미한다.
가지고 있는 모든 속성(= X, Features) 에 대해 분할 후 정보획득량을 계산하고, 이 값이 가장 큰 속성부터 분할의 기준으로 삼는다.
'ML Lecture > Supervised Learning' 카테고리의 다른 글
| Logistic Regression / 로지스틱 회귀 (0) | 2023.04.15 |
|---|---|
| Linear Regression / 선형 회귀 (0) | 2023.04.15 |